Automated Table Schema Optimization for Heterogeneous Statistical Datasets: A Hybrid LLM-Based Approach

Webpage: http://13.229.203.229
Project Background
Many spreadsheets used in social services, government, and NGOs are designed for human readability rather than machine processing. Visual choices—merged cells, multi-row headers, embedded subtotals, and ad hoc column names—make them easy to read but hard to analyze programmatically. This leads to two core problems: (1) inconsistent attribute names for the same concepts across datasets, and (2) ambiguous table structures where aggregates are mixed with individual records, confusing automated tools and LLMs.
The key challenge is structural, not just data quality. Structural transformation requires converting human-oriented layouts into machine-readable schemas: unmerging visually grouped cells, resolving multi-level headers, separating metadata and totals from observation rows, and standardizing attribute names across sources. Unlike value-level cleaning (typos, missing or inconsistent formats), this demands layout parsing, schema normalization, and transparent, auditable pipelines that can handle heterogeneous, real-world spreadsheets.
Our project directly targets these structural challenges. By producing consistent, tidy tables, we reduce manual data wrangling, improve LLM retrieval and reasoning, and enable faster, more reliable evidence-based analysis. Building on recent advances in table understanding and normalization, we focus on bridging the gap between research prototypes and deployment in organizations with diverse data and domain-specific conventions.
Project Objectives
- Develop an LLM-powered pipeline that automatically transforms messy spreadsheets into tidy data.
- Establish metrics that quantitatively assess layout quality based on physical coherence and attribute independence.
- Summarize and taxonomize common structural irregularities in real world industrial spreadsheets.
- Establish an evaluation framework measuring table “machine
readability” and construct a benchmark for measuring the effect of structural normalization.
Methodology
System Architecture

The system adopts a modular four-stage pipeline design to transform human-oriented spreadsheets into machine-readable formats. Four modules are included: Metadata Collector, Irregularity Detector, Schema Estimater, and Transformation Generator.
Technology Stack









User Interface




Evaluation
Dataset
The benchmark dataset comprises 90 real-world messy tables sampled from diverse sources, including Hong Kong government open data, Statistics Canada, Wikipedia, and industrial reports.
From these 90 reference tables, 328 QA pairs were automatically generated, comprising 180 lookup queries for specific value retrieval and 148 aggregation queries for group-level summation.
Questions are phrased as semantic natural-language intents without exposing the exact column names of the reference table, ensuring that schema differences between the reference and pipeline outputs do not unfairly penalize the evaluation.
Evaluation Metrics
Two complementary sets of metrics are used: structural tidiness metrics that assess layout quality independently of any downstream task, and code retrievability metrics that measure machine
queryability directly.
Structural Tidiness Metrics:



Code Retrievability Metrics
The Code Retrievability framework evaluates machine queryability by presenting an LLM with a semantic question and a fixed query template, and asking it to fill schema slots (column names and filter values) from the table’s column profile.

Result
Model Selection

Seven LLMs were evaluated as the pipeline core on the full benchmark dataset. The performance was measured by pipeline Execution Rate, Accuracy on the 328 QA pairs and the average table processing time.
Pipeline Evaluation for Qwen 3.6 Plus
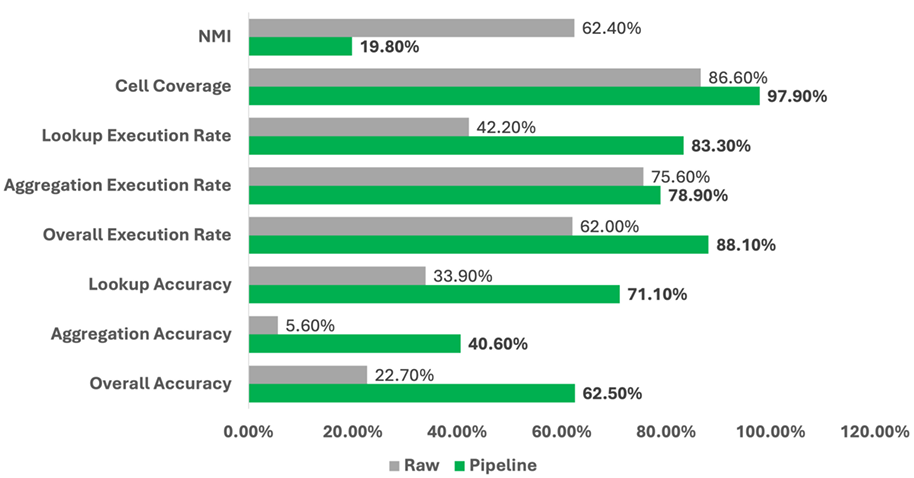
Using Qwen 3.6 Plus as the core model, the pipeline was evaluated on the full benchmark in a paired setting: Code Retrievability and structural tidiness metrics were computed on both the raw table and the normalized output for each table where the pipeline succeeded.
The structural and retrievability results confirmed that the pipeline produces measurable improvements along both dimensions. The gains in Code Retrievability demonstrated that structural normalization improves machine readability that is inaccessible on raw tables. The structural tidiness metrics confirmed that these improvements correspond to genuine layout transformation rather than superficial reformatting.